Weboldal JAVA Spring Boot alapokon - 2
Az előző részben megismerkedtünk a JAVA Spring folyamatának alapjaival, most pedig belevágunk a lecsóba, és létrehozzuk az adatbázis oldali táblákat, valamint kialakítjuk a kapcsot a leendő JAVA kódunk és az adatbázisunk között.
Mielőtt bármibe belekezdenénk, vessünk egy pillantást a POM.XML-re, amely a projektünkhöz tartozó dependency-ket tartalmazza, azaz azokat a már előre elkészített Spring modulokat, amelyeket fel fogunk használni a weboldal készítése során. Ez tartalmaz Security-t, JPA-t, Web starter projektet, PostgreSQL kapcsolatot, Tomcat kapcsolatot, Thymeleaf-et. Ezekről amint eljutunk ahhoz a részhez ahol szükség lesz rá, részletesebben is beszélünk. Jelen esetben a PostgreSQL kapcsolat amire szükségünk lesz, hiszen a PostgreSQL és a kódunk közötti kapcsolatot most alakítjuk ki.
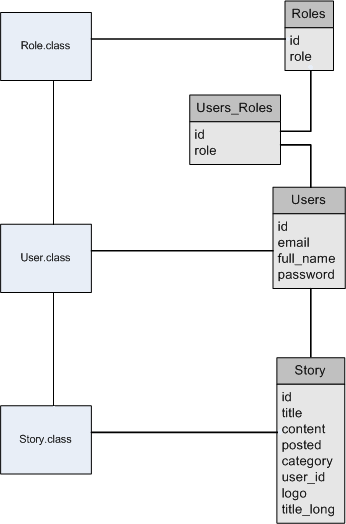
Adatbázisként tehát PostgreSQL-t használtam, de mindenki olyan adatbázist telepíthet, amilyent csak szeretne, értelemszerűen az egyes később leírt parancsok adatbázistól függően eltérhetnek, illetve ezzel együtt a POM.XML-t is módosítanunk kell attól függően, hogy milyen adatbázist használunk. Első körben létrehozunk 4 adatbázistáblát, amelyek egyfelől a weblapunk felhasználóit, jogosultságait fogják tartalmazni, másfelől pedig a weboldalon megjelenő bejegyzéseket. Azaz a weboldalunk teljes egészében ezeken az adattáblákon fog alapulni, minden adatot innen kap majd. Az adattáblák:
- users: a felhaszálóinkat tartalmazza. Mezői: id (integer, NOT NULL), email (character varying(100), NOT NULL), full_name (character varying(100), NOT NULL), password (text, NOT NULL)
- roles: a felhaszálóinkhoz rendelhető szerepköröket tartalmazza. Mezői: id (integer, NOT NULL), role (character varying(100), NOT NULL)
- users_roles: a users és a roles táblákat összerendelő tábla. Mivel egy userhez több role is rendelhető, illetve egy role több usert is tartalmazhat, szükséges a kapcsolótábla létrehozása. Mezői: user_id (integer, NOT NULL), roles_id (integer, NOT NULL)
- story: a weboldalon megjelenő bejegyzéseket, cikkeket tartalmazza. Mezői: id (integer, NOT NULL), title (character varying(100), NOT NULL), content (text), posted (date), category (character varying(30)), user_id (integer), logo character varying(50)), title_long character varying(150)). A title mező a bejegyzés címét, a content a bejegyzés szövegét, a posted a létrehozás dátumát, a user_id a felhasználót, a logo a cikkhez megjelenítendő képet, míg a title_long egy max. 150 karakter hosszú leírást tartalmaz a cikk tartalmáról.
Fontos, hogy a users tábla tartalmaz egy password mezőt, amelyet titkosítanunk kell. Erről bővebben korábbi bejegyzésemben olvashattok.
Az id mezőkhöz továbbá hozzunk létre egy szekvenciát:
CREATE SEQUENCE hibernate_sequence START 1;A létrehozott táblákba tegyünk is be pár adatot teszt jelleggel:
INSERT INTO "public"."users" ("id","email","full_name","password") VALUES ('1','teszt.elek@teszt.hu','Teszt Elek',crypt('1234', gen_salt('bf', 8)));
INSERT INTO "public"."roles" ("id","role") VALUES ('1','admin')
INSERT INTO "public"."users_roles" ("user_id","roles_id") VALUES ('1','1')
INSERT INTO "public"."story" ("id","title","content","posted","category","user_id","logo","title_long") VALUES ('1','Cím 1','Content 1', CURRENT_DATE,'JAVA','1','','Hosszú cím')Most, hogy az adatbázis oldallal készen vagyunk, JAVA oldalon meg kell teremteni az adatbázisok JAVA megfelelőit. Ennek érdekében a táblákhoz létrehozunk 1-1 POJO-t, amely tartalmazza a táblák mezőit JAVA objektumokként, gettereket és settereket, hogy elérjük és módosítani tudjuk az adatbázis táblákat, konstruktorokat, valamint egy toString függvényt, amely az objektumokat Stringként adja majd tovább a további rétegeknek. Hozzunk tehát létre egy Entity könyvtárat az ECLIPSE/STS-ben, ahova elhelyezünk 1-1 JAVA osztályt az adattábláknak megfelelően. A forráskódot lásd GitHub-on, az alábbi linkeken:
- User.java
- Role.java
- Story.java
Pár fontos dolog a forráskódok kapcsán:
- a @GeneratedValue és @Id annotációt használjuk az ID mezők esetében, ezzel jelezzük, hogy ID mezőről van szó, továbbá automatikusan generált értéket használunk az adatbázisban
- a User és a Story közötti kapcsolatot a Story oldaláról @ManyToOne, míg a User oldaláról @OneToMany(mappedBy = "user") annotációval jelezzük. Azaz ezzel jelezzük, hogy egy User több Story objektumot is tartalmazhat. - az User és a Roles közötti kapcsolatot a @ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER), valamint @JoinTable( name ="users_roles", joinColumns = {@JoinColumn(name="user_id")}, inverseJoinColumns = {@JoinColumn(name="roles_id")} ) annotációval jelezzük.
A CascadeType.ALL értelmében ha egy objektumot módosítunk az egyik táblában, akkor az módosul a kapcsolódó tábla esetében is. A FetchType.EAGER esetében pedig az történik, hogy ha az egyik tábla tartalmát lekérdezzük, akkor az ahhoz kapcsolódó táblának is minden rekordja lekérésre kerül (nagy táblák esetén ezért érdemes lehet a FetchType.LAZY-t használni).
A @JoinTable esetében pedig meghivatkozzuk a users_roles táblát, annak kapcsoló mezőit, hogy a Users és a Roles objektumok között is meglegyen a kapcsolatunk. Végül az átvett szerepköröket egy HashSet-bet tároljuk el: private Set
A JAVA és az adatbázis között még meg kell határozni a kapcsolódási paramétereket is, amelyet az application.properties-ben szükséges megtenni, értelemszerűen az alábbi felhasználónevet, jelszavat és adatbázis sémát az általunk létrehozotthoz szükséges igazítani:
spring.datasource.platform=postgresEzzel igazából létre is hoztuk az adatbázis és a JAVA közötti kapcsolatokat, a következő részben nekiesünk a Repository-nak, azaz létrehozunk JPA féle SQL lekérdezéseket, amelyeket az imént létrehozott POJO-kon keresztül érünk el az adatbázisból, azokat pedig aztán továbbadjuk majd a Services réteg felé, de az már egy következő lépés lesz.
spring.datasource.url=jdbc:postgresql://localhost:5432/blog
spring.datasource.username=blog
spring.datasource.password=1234